
Written by Nono Martínez-Alonso — May 10, 2017
Learn more about the tools, technologies & workflows used in this project here ↗︎.
And check out my Machine Intelligence YouTube playlist ↗︎.

← Use the arrow keys to navigate. →
In May 2017, I graduated from the Graduate School of Design at Harvard University, where I studied a Master in Design Studies with a focus on Technology. This page is an adaptation of my talk to present my master's thesis, advised by Panagiotis Michalatos.
Hi there! My name is Nono Martínez Alonso. Let me tell you what Suggestive Drawing is all about.
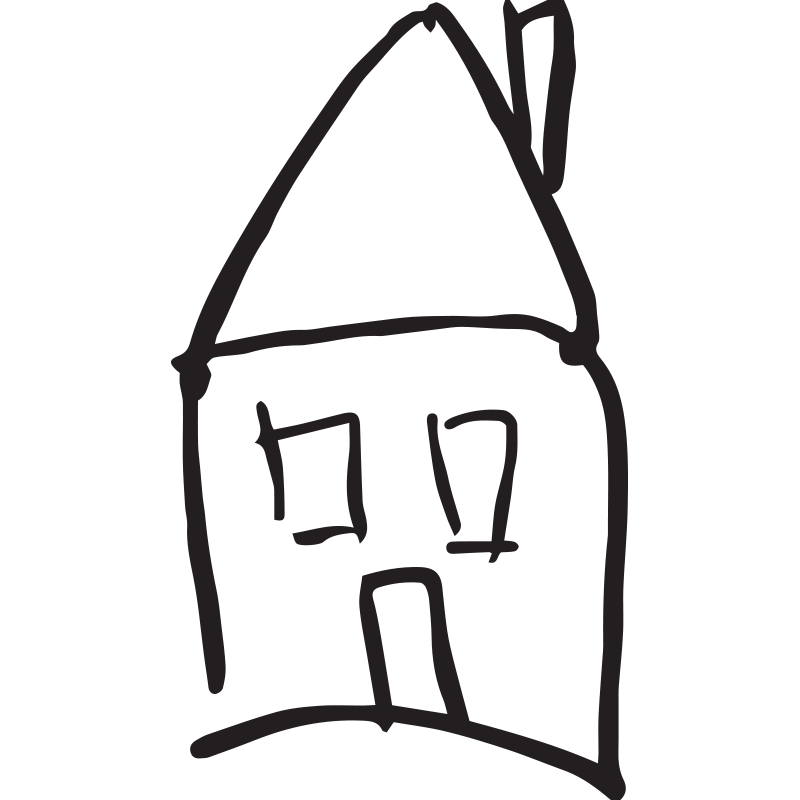
We use sketching as a medium to represent the world.
Design software has enabled drawing features not available on physical mediums. Layers, copy-paste, or the undo function, for instance, make otherwise tedious and repetitive drawing tasks trivial. Digital devices map actions into accurate drawings but are unable to participate in how we represent the world as they don't have a way to perceive it.
The artificial intelligence boom is being propelled by the availability of faster, cheaper, and more powerful parallel processing power and the rapidly growing flood of data of every kind.
In recent years, the field of artificial intelligence has experienced a boom. By processing thousands of pictures, a computer is able to learn about certain aspects of the world and make decisions in a way that resembles the human way of thinking. Machine learning is ubiquitous and comes with new ways to program and interact with machines. To me, this was an opportunity to teach machines how to draw—by observing images and sketches of real objects—so they can be participants in the drawing process and not just mere transcribers.
In order to explore this, I developed a suggestive drawing environment, in which humans can work in synergy with bots, and each bot has a specific character, and a non-deterministic, semi-autonomous behavior.

This environment explores the user experience of drawing with machines.

And escapes the point-and-click paradigm with continuous interactions.
I believe this approach will enable a new branch of creative mediation with machines that can develop their own aesthetics and gather knowledge from previously seen images and representations of the world.
Let's now see what would the role of machines and artificial intelligence be in the creative process and how they can be helpful.


Patrick Henry Winston is the Ford Professor of Artificial Intelligence and Computer Science at the Massachusetts Institute of Technology (MIT).Back in the fall of 2016, I took artificial intelligence courses both at Harvard and MIT. Right before the winter break, I biked under the cold weather of Cambridge toward Frank Gehry’s Stata Center building to visit Patrick Winston in his office. “Each technological advance brings with it new ways,” Winston said, and mentioned how design or drawing were not an exception.
When approaching the blank canvas, the artist explores a vast space of drawing possibilities. There is a way of thinking inherent to our brains that occurs during this creative process. Winston’s intrigue was on how this human way of generating and evaluating options looks like, and—more importantly—what its equivalent computational techniques are. This project explores what modes of creativity can be enabled by artificial intelligence.
Deterministic algorithms expect a series of input parameters from us in order to output a result. The act of drawing is an evolving, open-ended process in which we have an idea of where we want to go but no clear destination. We can't tell the computer what we want as a finished product. The question is, then, how do we communicate our intentions to the computer when they are not clear? Instead of using functions that solve problems, computers need to be able to interpret our input when it is fuzzy, as happens when we give it drawing strokes.
Some times we have a well defined goal and way to solve our problem.

Without a predetermined end, we reach stable states through suggestions and reflections in non-deterministic ways that resemble the creative process.
The canvas is not a projection screen where we project our vision of what we want to draw. It is more like a mirror where we draw strokes and, at each step, re-evaluate what our drawing looks like in order to continue. The machine can use analogue modes of thinking to recognize what we are drawing and help us move forward.
To perform actions, machines require orders from us. We instruct computers to execute commands by clicking a mouse, typing on a keyboard, or tapping a screen. This way, a computer receives the exact same input from any person who "left-clicks" or presses the Enter key, behaving, as a result, in a highly deterministic manner.
Machines and inputs force us to think in discrete units of actions—clicks and commands—and tend to describe information with discrete and sparse representations.

These interfaces impose a discretization of action, time, and human experience, in which human activity happens in well-defined, exclusive, discrete steps. There is a time in which you request a command and a time in which the command is executed. This process resembles Greek geometric constructions, where a series of discrete steps solve a problem. Today, new hardware and software allow for richer interactions with machines: commands and actions can happen concurrently without interrupting each other.
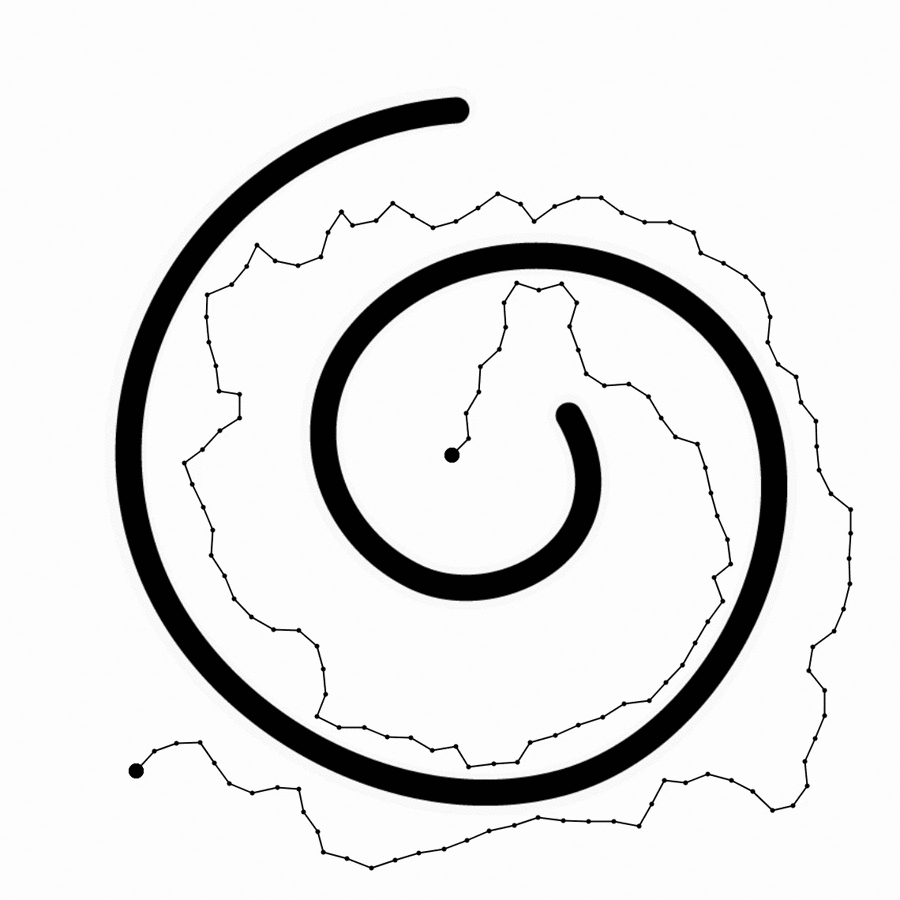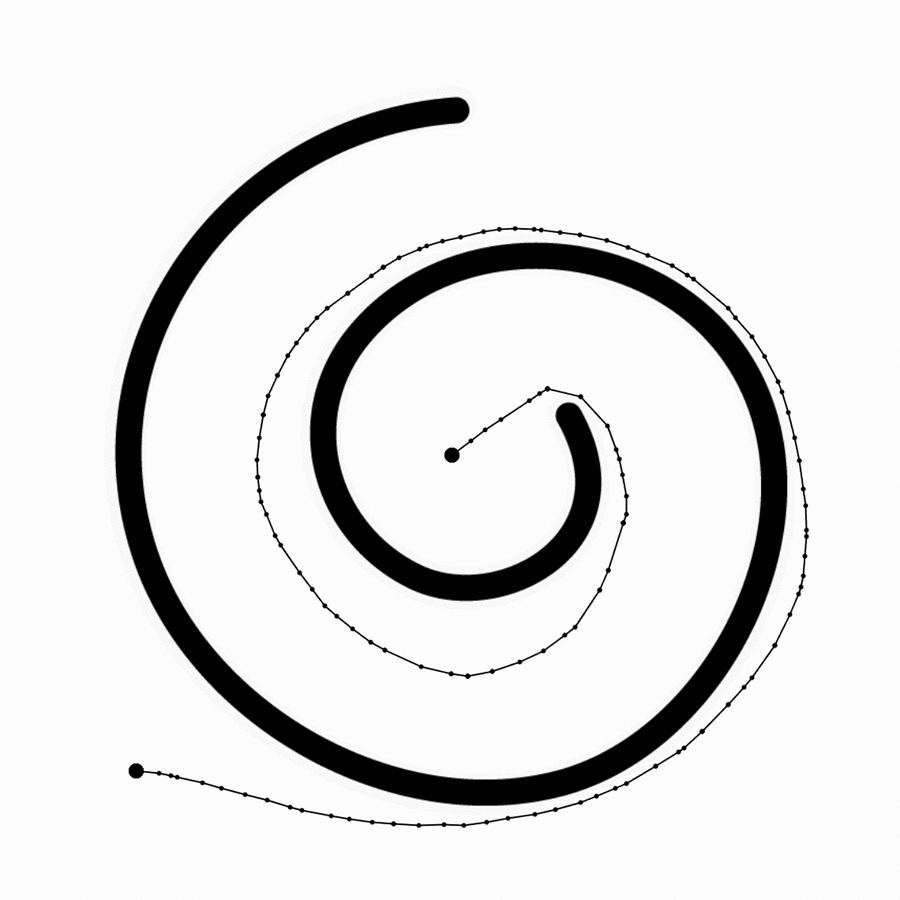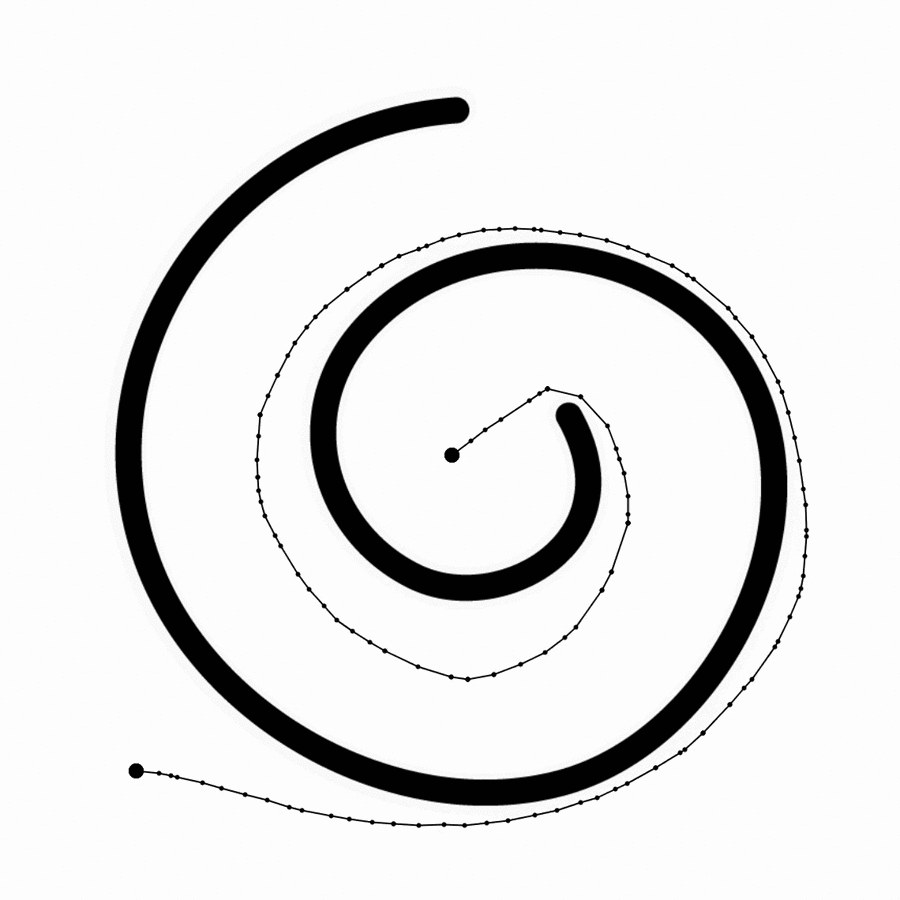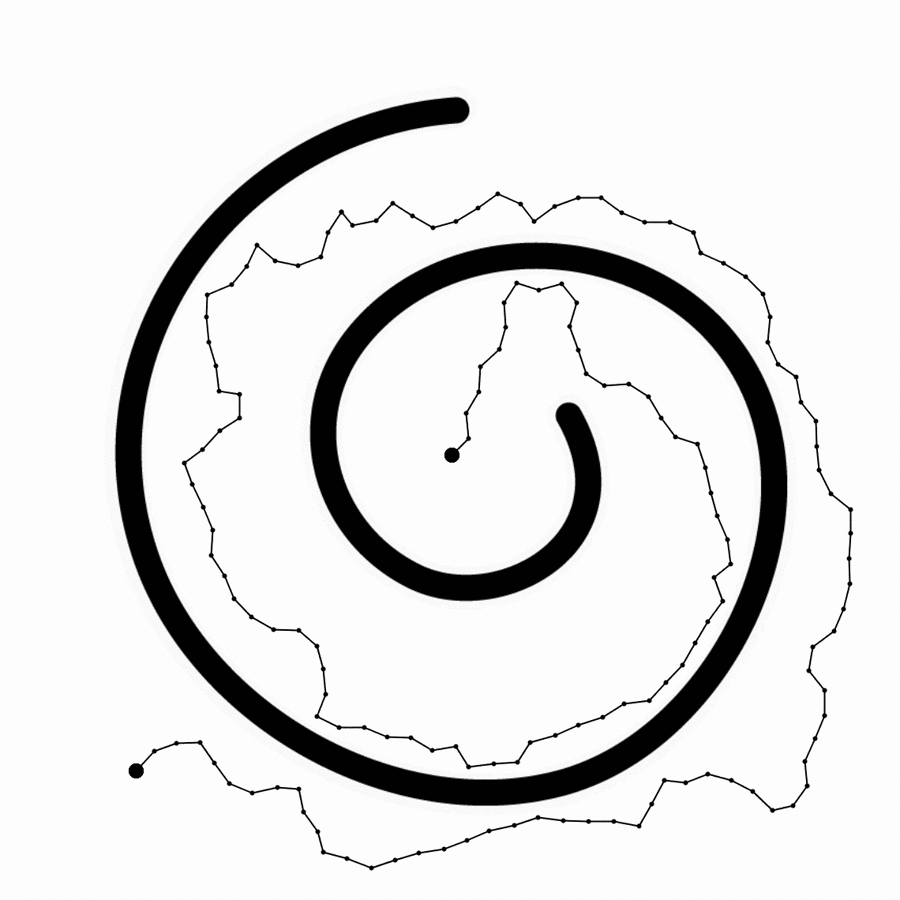
Computer-Aided Drawing systems are based on sparse representations of information with infinite precision. A line is defined by two clicks—start and end points—but contextual information about how, where, or when those points where created is usually not kept.

Two clicks.

A continuous signal.
In expressive mediums, a continuous signal is more useful for artificial intelligence because it provides context. I used a stylus to capture hand-sketches as a continuous signal, storing position, inclination, pressure, and temporal data to create dense representations of the context in which actions take place, where nuances and accidents become important.

In the twenty-first century, media was mainly about passive consumption of content. With the appearance of the Internet, the promise was that being interconnected would lead to a collective production of content.

But collective forms of creativity are not new. They existed in the pre-industrial world. For instance, the American tradition of quilt making expresses the collective expression of communities at a given moment in time.

Greatly propelled by online content creation platforms, this collective production is emerging again as new collective forms of creativity. We consume content created by a collective, where participants belong to different areas of the world.
Some of these platforms, such as Google Docs or Figma, make human collaboration a possibility.

And some include bots—both humans and non-humans participating.

A good example of this is Reddit Place (a form of folk art). In this seventy-two hour long experiment, each user could change the color of one pixel every five minutes. Self organizing communities, comprised of both human and non-human agents, participated on a canvas of one million pixels.
Talkomatic was created by Doug Brown and David R. Woolley in 1973 on the PLATO System at the University of Illinois. It offered six channels, each of which could hold up to five participants. (Wikipedia) The chat room was the first technology to allow users from all over the world to converse online. Each of these rooms would serve as a real-time communication channel were clients could message others. The first chat room—Talkomatic—was created in 1973. During the 1900 and early 2000s, IRC was popularized—a system created by Jarkko Oikarinen in Finland.
*According to the English Oxford Dictionary, a bot is an autonomous program on a network (especially the Internet) which can interact with systems or users, especially one designed to behave like a player in some video games.Due to their utilitarian aspect, the use of bots in chat rooms increased. These so-called bots (autonomous programs on a network*) could replace human administrators and perform numerous tasks in communication channels. Users would type commands in a command-line interface to get help from a bot or to make them perform actions such as signing them to a chat server or assigning them a user handle. Bots are responsible for the maintenance and house keeping of chat rooms, and also support users and control how they behave.
Today, we have expectations for bots that go beyond these utilitarian tasks. We expect bots to be part of the group; to interact with us as another human would do and express their own character.

As I previously mentioned, I wanted to see how this participation of human and non-human agents could take place in the creative process. In order to explore this, I developed a sketching application that incorporates artificial intelligence.
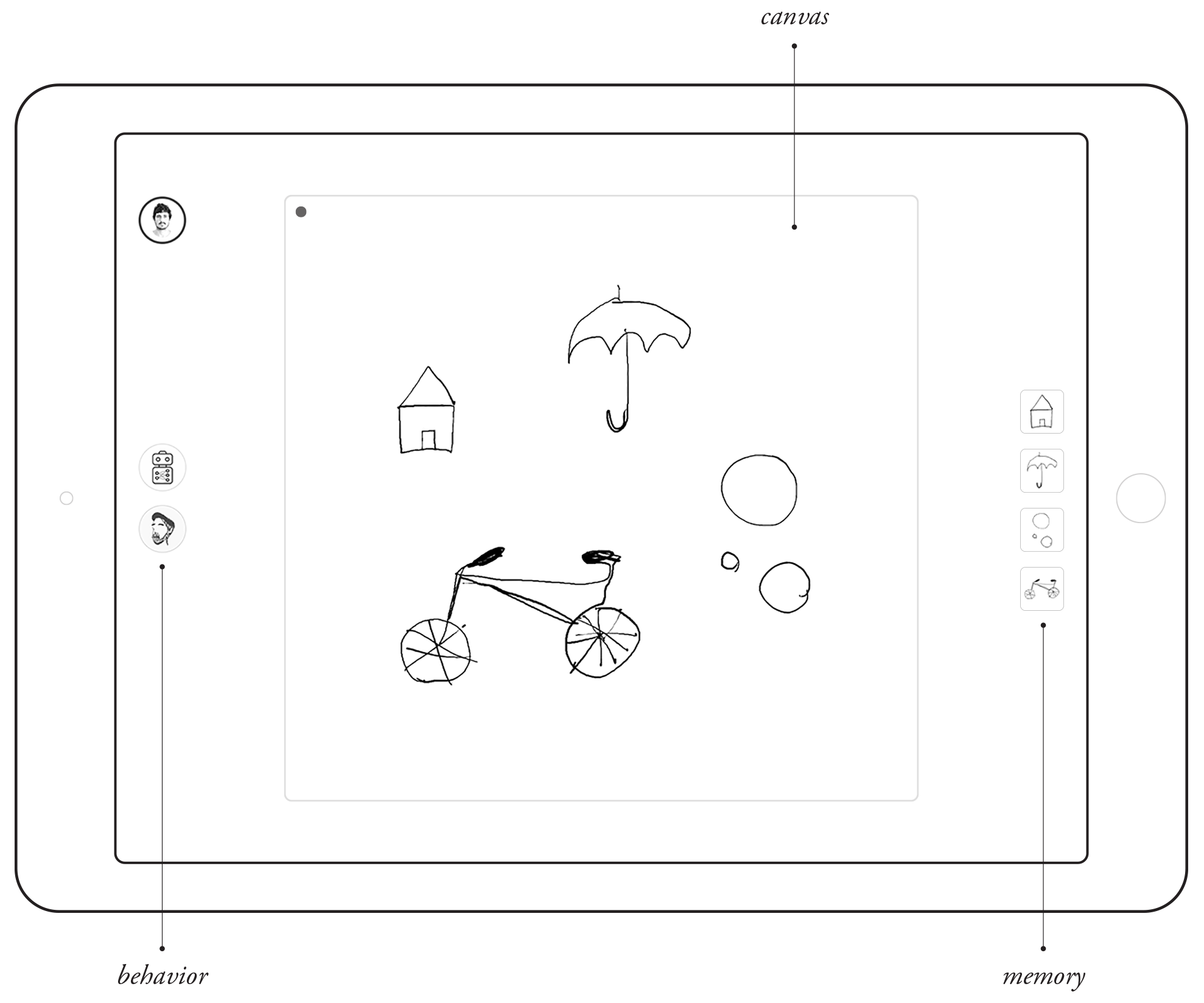
The application incorporates behavior—humans and bots—but not toolbars, and memory—as it stores and provides context for what has been drawn—but no explicit layer structure.
Actions are grouped by spatial and temporal proximity that dynamically adjusts in order not to interrupt the flow of interaction.
The system allows users to access from different devices, and also lets bots see what we are drawing in order to participate in the process.
In contrast to interfaces of clicks and commands, this application features a continuous flow of interaction with no toolbars but bots with behavior. What you can see next is a simple drawing suggestion: I draw a flower and a bot suggests a texture to fill it in.
In this interface, you can select multiple human or artificial intelligences with different capabilities and delegate tasks to them.

Let's take a look at different suggestive drawing bots that could guide us through the drawing process.


We interact with drawing bots. Each of them has a specific behavior which was acquired during training. The following list matches each bot with how it processes our sketches.
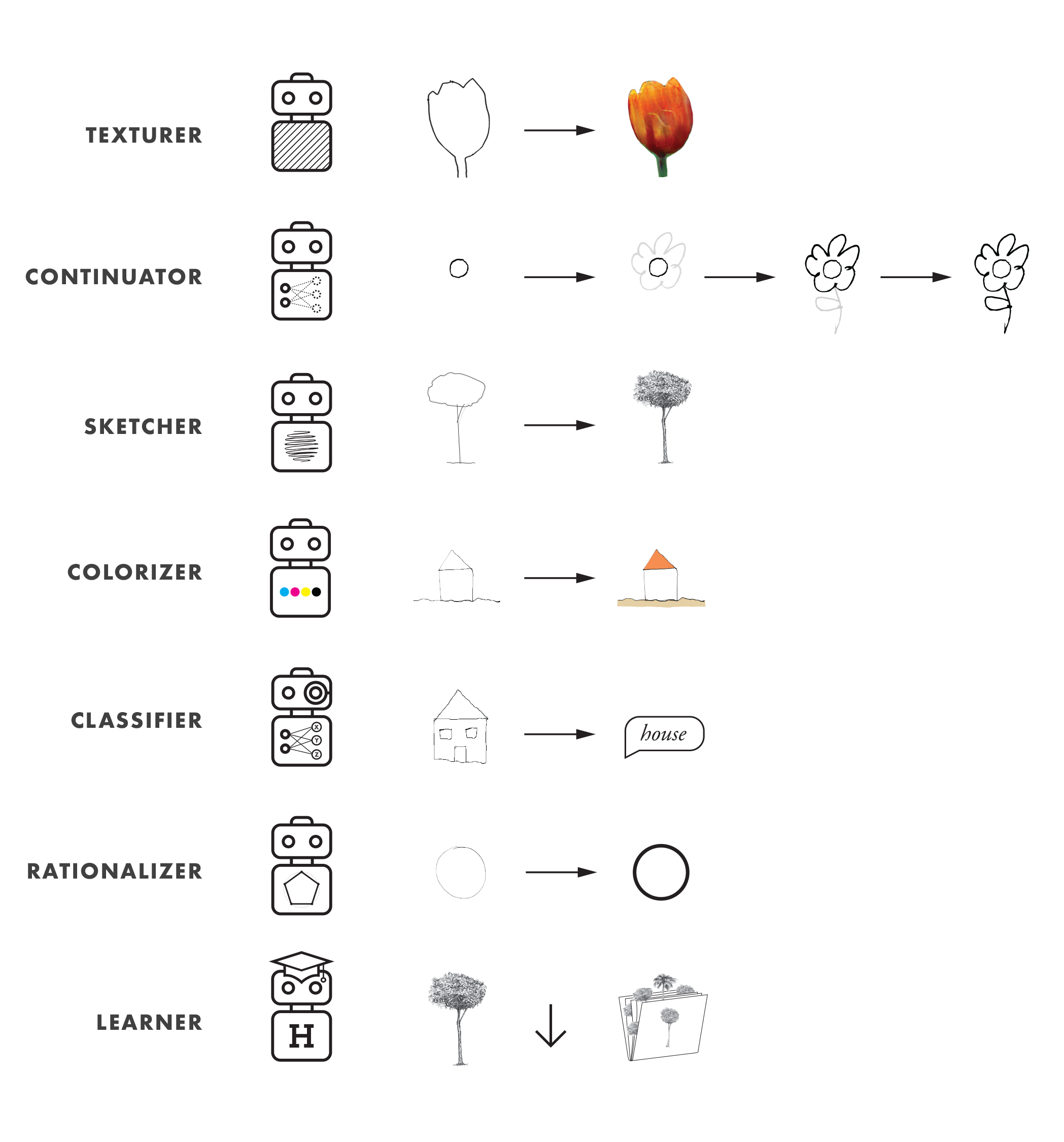
For the scope of this project, I developed three functional drawing bots—texturer, sketcher, and continuator—that suggest texture, hand-sketched detail, or ways to continue your drawings, respectively. I also experimented with classifier, a bot that classifies hand sketches using different inference models. Lastly, I used the learner bot to sort what is being drawing in order to use existing drawings for training new bots according to a desired drawing character. (Texturer, sketcher, and continuator use pix2pix-tensorflow, and classifier uses a re-trained version of TensorFlow's inception model.)
Let's see real examples of the developed bots working—texturer, sketcher, and continuator—, and conceptual videos of the rest—colorizer, classifier, and rationalizer.
Texturer uses pix2pix-tensorflow to generate a textured drawing from the edges of a hand sketch. The bot is capable of working with different models—trained in different sets of images—by selecting the desired model in its contextual menu. It is important to note that each training set of pix2pix consists of hundreds of pairs of images—one image of the pair being a textured object and the other an edge representation of it. For texturer, the textured objects are real photos and their edge representation is generated with edge detection algorithms applied to the photos.
In the case of texturer and the two following bots (sketcher and continuator) the application communicates with a back-end server running conditional adversarial neural network with TensorFlow, using the pix2pix-tensorflow architecture.
As mentioned before, this bot has been trained to map sketches to textured objects. When we provide the bot with a new outline, it generates a new texture for it. What is important to note here is that the texture our outline is filled with is not a pre-existing image but a new one, generated by a neural network according to what it learned during training.
As you can see in the video, I trained the model with different types of flowers (daisies, tulips, sunflowers, roses, dandelions) but also with abstract art and dresses from The Metropolitan Museum of Art.
I trained these models myself. It is fair to say that, because I'm familiar with texturer's training set, I'm trying to make the bot work as it is supposed to work. (If it's been trained with daisies, for instance, I draw a daisy.) But what happens if we don't use a bot how it is supposed to work?
The following video presents unexpected uses of texturer models. Even when a bot has been trained to draw flowers or dresses, we can explore other suggestions it might have to, for instance, fill the texture of a house, a car, or abstract shapes.
Sketcher also uses pix2pix. This time, pix2pix has been trained on hand-sketches of trees and urban scenes. The tree training set consists on sixty four hand-drawn trees by an artist who collaborated in the project—Lourdes Alonso Carrión. The urban scene training set consists on urban sketches done by multiple sketchers, including myself.
As you can see in the video, we obtain hand-drawn detail of a tree by sketching its outline. In the case of the urban scenes, the bot tries to watercolor them.
Continuator suggests ways to continue our drawings that makes sense in the context of what we are drawing. I trained this bot with a series of successive steps of the growth of a tree generated with Processing. First, we map the trunk to the trunk with long branches, next we map this state to one that adds smaller branches, and, lastly, we map this state to one that adds leaves. Instead of training on single pairs for each tree—a to b, like former bots—, continuator is trained on a series of future steps—a to b to c to d. We can say that continuator guides us to continue drawing according to the knowledge embedded in its training set.
Colorizer could be also developed using pix2pix. It is meant to fill your outlines with colors that make sense according to what you are drawing.
Classifier uses a classification neural network to recognize what you are sketching by giving it a tag. This tag could give this or other bots information about what you intend to draw to selectively swap between different trained models. This is, classifier agent work together with texturer so texturer suggests flower textures when you are drawing a flower, without having to explicitly select a flower model yourself. As we can see on the next video, rationalizer could also make use of a classification model to discern between different shapes and geometries in order to replace them with a cleaner version of it.
Let's now see what the challenges for training these bots are.

For bots to be capable of providing drawing suggestions, they need to be trained. We may teach them to identify what object we are drawing, or to continue or transform our sketches in different ways. As we've seen before, bots can be trained to add texture, color, or even detail to our hand sketches, and we can imagine a lot more applications.
The first problem that we face before training a bot is the need for a data set: a set of images from which bots can learn from. We can either find a data set, by downloading pictures from the Internet or a data set compiled by someone else, or we can generate it ourselves—by processing of images in batches or, like the case of the trees, hand sketching them all ourselves.
What needs emphasis is the fact that in the realm of machine learning and artificial intelligence, training sets become part of the design process. It is the designer who—by selecting a set of images—programs a bot.
This first training set, generated with over a thousand images of dresses from The Metropolitan Museum of Art's collection, is an example of mapping edges generated with Mathematica to its corresponding textured image. In the process of training, pix2pix learns how to map the features of the image on the left (the edges or outlines of a dress) to its corresponding texture (the actual photography of the dress).
The following training set is the core behavior of sketcher. The outline edge of each of the trees was generated by processing the hand sketch with Mathematica and applying an edge detection algorithm. In this case, both outline and sketch resemble the way we would draw a tree—with and without detail. While this might sound obvious, these data sets are slower to generate as they are hand-sketched, but this process allows the artist to transfer a particular aesthetic to a given bot.
Lastly, I'd like to show you a training set generated using daisies from a creative-commons licensed flower photos provided by TensorFlow.
Here, I automate the edge detection of six hundred images with Mathematica to extract their edges. But this edges are not as clear as the ones obtained for the tree data set, and don't resemble the way a human would draw a flower either. Still, texturer seems to performs fairly well, probably because the color and shape of the daisies in the data set are highly consistent.

The development of these bots wouldn't have been possible without the pix2pix code open-sourced by Isola et al, and the pix2pix-tensorflow port open-sourced by Christopher Hesse.
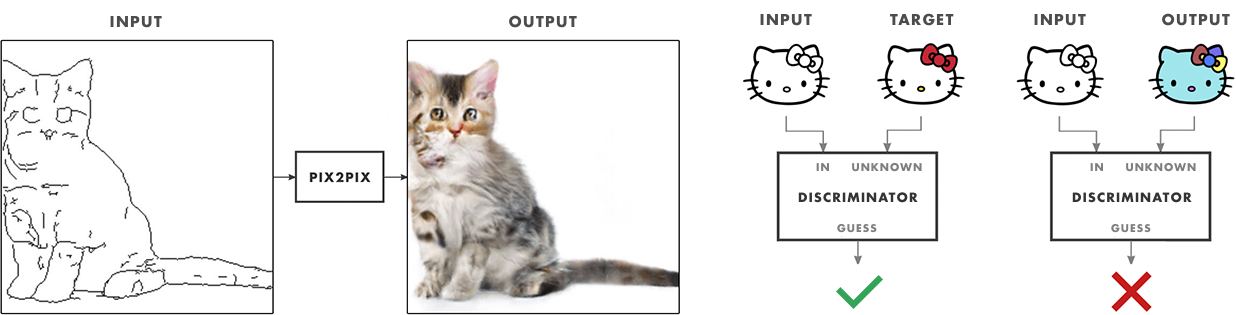
Systems like pix2pix enable a new way of programming the machine by example. Artists and designers can fine tune the behavior of an algorithm by feeding it with images, without writing a single line of code. This, I believe, goes in line with what Isola et al express in Image-to-Image Translation with Conditional Adversarial Networks:
As a community, we no longer hand-engineer our mapping functions, and this work suggests we can achieve reasonable results without hand-engineering our loss functions either. […] Just as a concept may be expressed in either English or French, a scene may be rendered as an RGB image, a gradient field, an edge map, a semantic label map, etc. In analogy to automatic language translation, we define automatic image-to-image translation as the problem of translating one possible representation of a scene into another, given sufficient training data.

Because it can be hard to find good data sets for specific needs, I developed learner, a bot that learns as we sketch and stores our drawings as organized data sets to train other bots. Learner doesn't actually draw anything but gathers drawings to train new bots like texturer, sketcher, or continuator.

To train classifier we just need to group multiple drawings of a given shape or thing in order to be able to recognize it when we draw it in the future.

And to train continuator we can use a series of consecutive drawings in the process of drawing something that is composed of multiple strokes. As mentioned before, this training set was artificially drawn with Processing.
As we can see in the following video, the environment stores every single drawing in a timeline. We could select certain pieces from the drawing history to train new bots on specific drawing patterns.
Many of these drawings were made by other artists, and manage to express the character of all of its participants. The human uses his particular drawing style. Then the bot accommodates its suggestions to it.
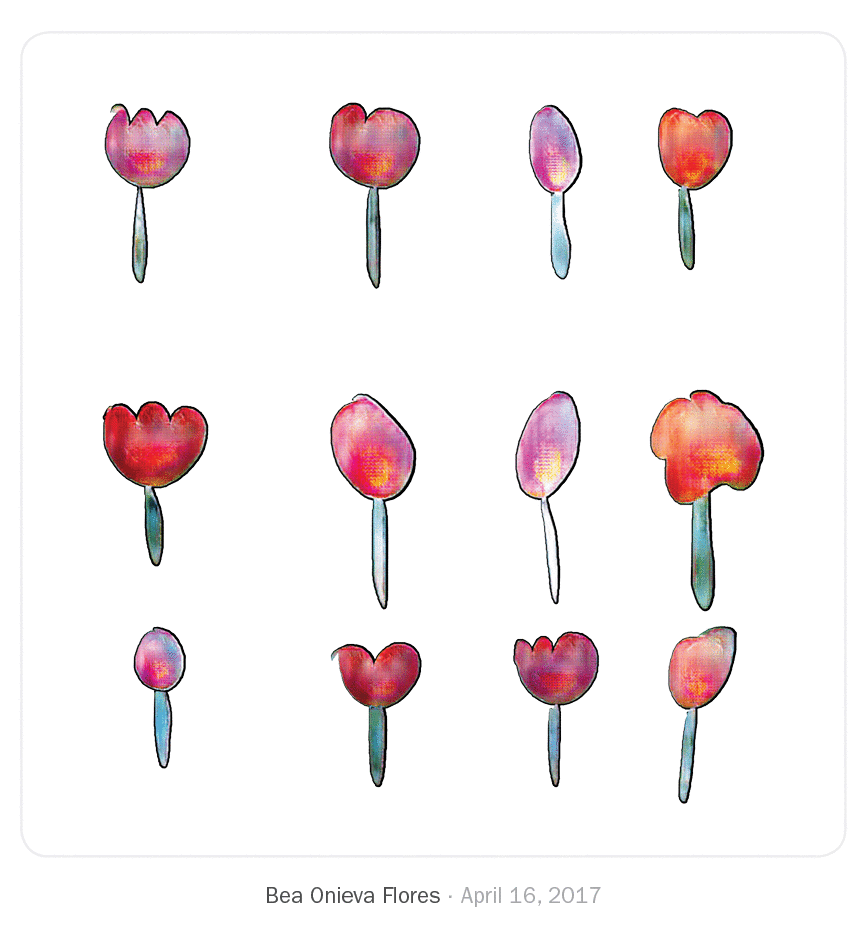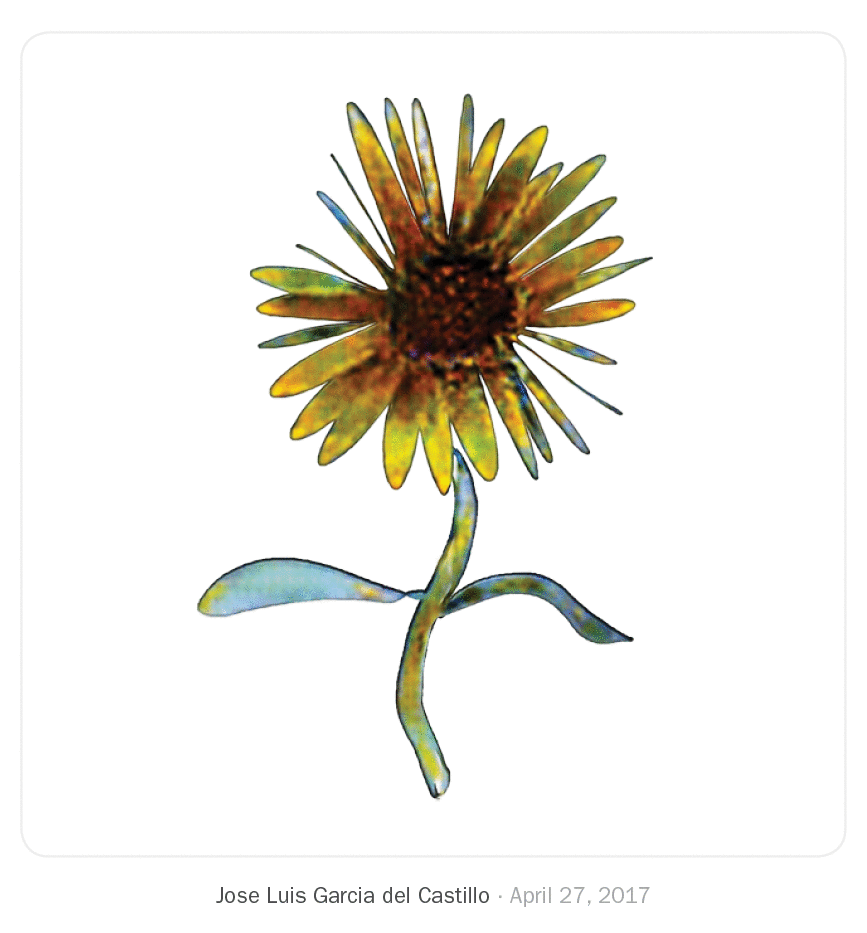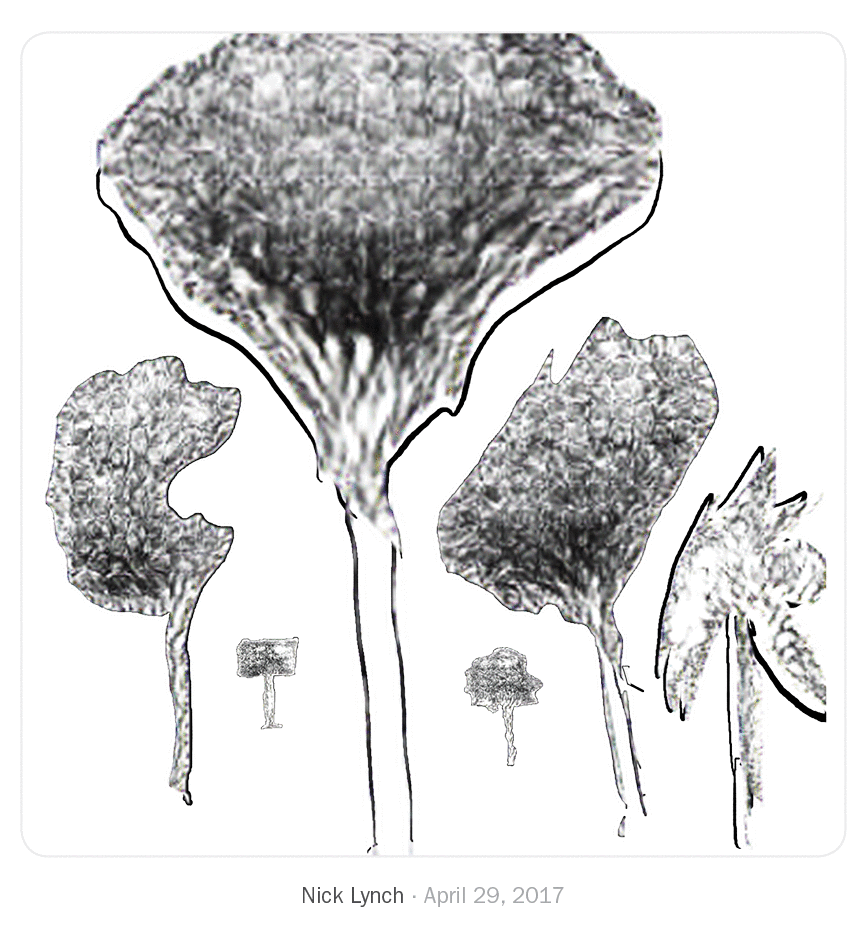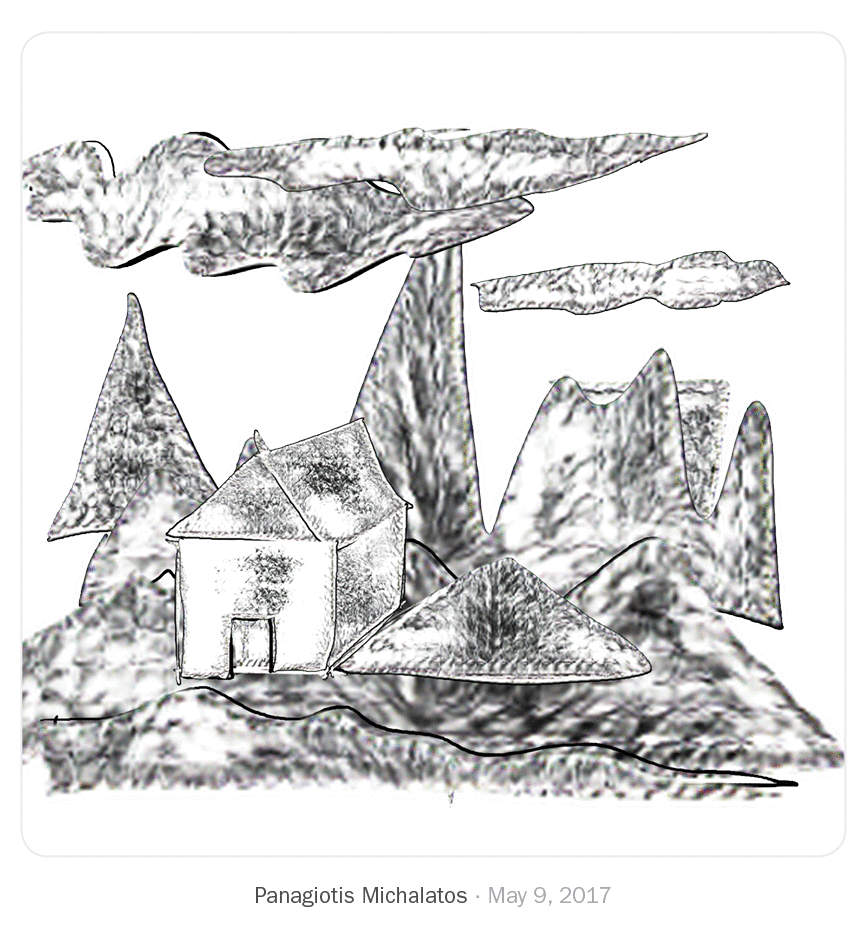
We just saw what other artists and designers have done in this drawing environment. After using the system for two months, I found myself experimenting with new drawing techniques and compositions I don't usually do.

One example is Croquetilla—a side project I work on. In this project, I tend to illustrate this character with simple line strokes and geometric shapes, and, rarely, using flat colors. My illustrations, I believe, obtained a brand new character—full of color—when I joined forces with texturer.
It's interesting to note how—even thought I hadn't trained any pix2pix model to draw hair, hearts, or the sun—I drew hair in the first illustration with a model trained on dandelions, the sun with the daisies model, and hearts in the second illustration with the roses model. Exploring the different models bots were using, I familiarized myself with unexpected behaviors that I could then use to my advantage.
I'd like to finish by expressing my view of where I believe machine intelligence and its application to the art and design fields are going.
This project presents one possible way for artists and designers to use complex artificial intelligence models and interact with them in familiar mediums. The development of new models and the exploration of its potential uses is a road that lies ahead. As designers and artists, I believe it is our responsibility to envision and explore the interactions that will make machine intelligence a useful companion in our creative processes.

In order to make this manuscript easier to understand by a wider audience, I've left aside as much technical information as possible, hopefully, without compromising the comprehension of the project.
Go is an open source programming language initiated by a team at Google 2007. Among other reasons, Go seemed the right language to use in this project, mainly because of its built-in concurrent programming features.However, an important part of this project was the development of a working prototype. The project runs a Go server on the back-end, allowing humans and bots to interact with drawings using a web socket connection. Humans connect through a Swift client developed for iOS devices and bots connect through a Go client.
The Go server handles HTTP requests, a REST API, web socket connections, a MongoDB database, and other operations. The Swift client allows humans to draw in collaboration with other participants. The Go client handles the behavior of drawing bots, their drawing interactions, and the remote execution of machine learning models, such as pix2pix with TensorFlow. For an in-depth report of the tools, technologies, and workflows used in this project, refer to the Technical Report.
Thanks so much for reading—really. This manuscript intended to help you understand what Suggestive Drawing is all about. I hope it did.
You can Download a PDF version of this manuscript, in which videos and animated loops won't play, of course. As I mentioned before, I also provide a supplemental Technical Report online for the tech-savvy—or for those who would like to dive in and learn more about how the working prototype of this project was developed.
Thank you so much for reading.


{kind=link}
{kind=link}