I have an Apple M3 Max 14-inch MacBook Pro with 64 GB of Unified Memory (RAM) and 16 cores (12 performance and 4 efficiency).
It's awesome that PyTorch now supports Apple Silicon's Metal Performance Shaders (MPS) backend for GPU acceleration, which makes local inference and training much, much faster. For instance, each denoising step of Stable Diffusion XL takes ~2s with the MPS backend and ~20s on the CPU.
When manipulating semantic segmentation datasets, I found myself having to downsize segmentation masks without adding extra colors. If the image is cleanly encoded as a PNG, only the colors representing each of the classes contained in the label map will be present, and no antialias intermediate colors will exist in the image.
When resizing, though, antialias might add artifacts to your images to soften the edges, adding new colors that don't belong to any class in the label map. We can overcome this problem loading (or decoding) input images with TensorFlow as PNG and resizing our images with TensorFlow's NEAREST_NEIGHBOR resizing method.
(You can find a list of all TensorFlow's resize methods here, and an explanation of what each of them does here.)
import tensorflow as tf
# Read image file
img = tf.io.read_file('/path/to/input/image.png')
# Decode as PNG
img = tf.io.decode_png(
img,
channels=3,
dtype=tf.uint8
)
# Resize using nearest neighbor to avoid adding new colors
# For that purpose, antialias is ignored with this resize method
img = tf.image.resize(
img,
(128, 128), # (width, height)
antialias=False, # Ignored when using NEAREST_NEIGHBOR
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR
)
# Save the resize image back to PNG
tf.keras.preprocessing.image.save_img(
'/path/to/output/image.png',
img
)
"Less than 50 days after the release YOLOv4, YOLOv5 improves accessibility for realtime object detection." Read the Roboflow post.
Here are resources that are helping me get started with machine learning, as well as a few that I would have loved to have known about earlier. I periodically update this page with new resources. If you have good ones, let me know!
A summary of terms, algorithms, and equations. (I barely understand the equations.=) These sheets, developed by Afshine and Shervine Amidi, differentiate between artificial intelligence (AI), machine learning (ML), and deep learning (DL), but many concepts overlap with each other. See this Venn diagram.
I highly recommend the book I'm currently reading, written by an ex-Googler who worked on YouTube's video classification algorithm. It's dense, but it introduces you to all relevant artificial intelligence, machine learning, and deep learning concepts and guides you through preparing custom datasets to train algorithms, as well as a bit of data science, I suppose. At the same time, it introduces you to three of the most-used machine learning frameworks—Sci-Kit Learn, Keras, and TensorFlow. This is the one I started using on my day-to-day job when I became an ML Engineer, developing and releasing machine learning models for production. Similar frameworks include Caffe and PyTorch, with the latter being used by Facebook developers. (Thanks to Keith Alfaro for the recommendation.)
I got started with machine learning by trying open-source algorithms. It's common to visit the GitHub repository corresponding to a paper and give it a try. Two examples are Pix2Pix (2016) and EfficientDet (2020). You can try using their code as is, then attempt to use a custom dataset for training and see how the model performs for your specific needs.
TensorFlow re-writes many of these models and makes easy-to-follow tutorials.
Well, this is happening today.
Even though our workshop is listed in the North-South Americas Workshops page, I'm tuning in from Málaga, Spain, where I live and work, remotely.
Jose Luis, Nate, and guest speakers will be joining from the US. Those include Elizabeth Christoforetti & Romy El Sayah, Ao Li, Runjia Tian, Xiaoshi Wang & Yueheng Lu, and Andrew Witt.
The format of our workshop has been widely adopted by numerous organizations as an alternative to the cancelation of on-site conferences, workshops, and other gatherings.
Zoom conference rooms miss many of the nuances present in in-person events, yet I feel they enable a new kind of interaction in which people who wouldn't have been able to cross the Atlantic are now a click away from hopping into a live conference with us. (No need to book plane tickets and accommodation, and seats don't necessarily need to be limited.)
As suggested by Jose Luis, ours are a series of non-technical lectures and demos. We've organized a one-day workshop in which we'll share our views on the role of machine intelligence in architecture, art, and design, commenting on state-of-the-art projects, tools, and machine learning models that are here to stay with us.
While preparing this workshop, I recorded two technical, hands-on coding tutorials as I was building the Pix2Pix & RunwayML drawing app we'll showcase today, using Glitch, Paper.js, RunwayML, and Pix2Pix, among other technologies. (I've published Part 1 and Part 2 so far.)
Visit our workshop page to see the most up-to-date schedule.
I hope you'll join us.
Stay in touch for future events.
Just came across this machine learning (and TensorFlow) glossary which "defines general machine learning terms, plus terms specific to TensorFlow."
I recently got Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition by Aurélien Géron as a recomendation from Keith.
This second version updates all code samples to work with TensorFlow 2, and the repository that accompanies the book—ageron/handson-ml2—is also updated frequently to catch up with the latest updates.
Just the Python notebooks on that GitHub repository are super helpful to get an overall on state-of-the-art machine learning and deep learning techniques, from the basics of machine learning and classic techniques like classification, support vector machines, or decision trees to the latest techniques to code neural networks, customizing and trained them, loading and pre-processing data, natural language processing, computer vision, autoencoders and gans, or reinforcement learning.
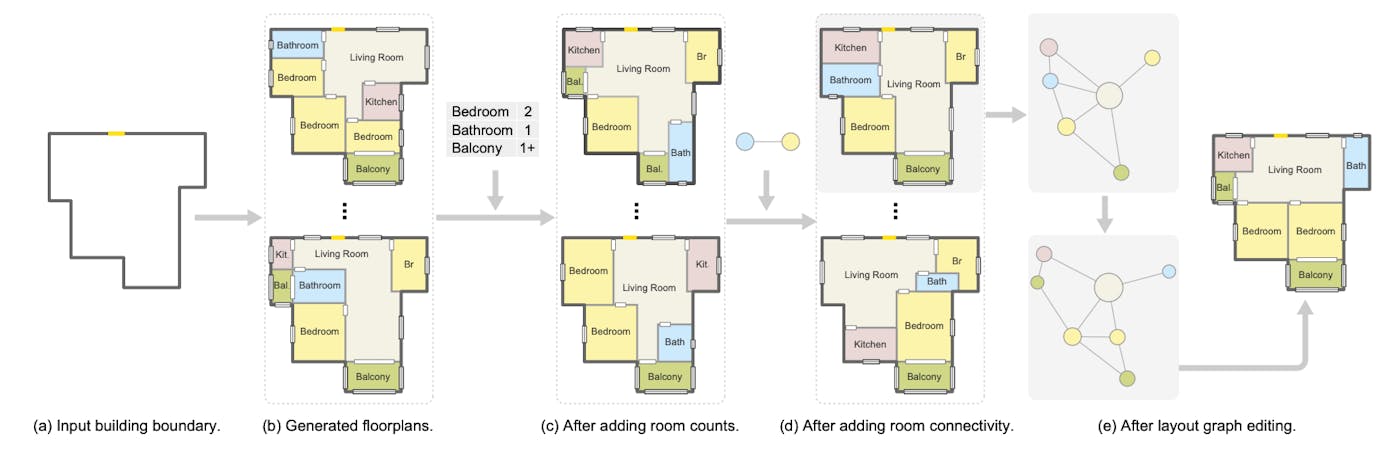
Nice work from Shenzhen, Carleton, and Simon Fraser Universities, titled Graph2Plan: Learning Floorplan Generation from Layout Graphs, along the lines of #HouseGAN. Via @alfarok.
Our deep neural network Graph2Plan is a learning framework for automated floorplan generation from layout graphs. The trained network can generate floorplans based on an input building boundary only (a-b), like in previous works. In addition, we allow users to add a variety of constraints such as room counts (c), room connectivity (d), and other layout graph edits. Multiple generated floorplans which fulfill the input constraints are shown.
We propose In-Domain GAN inversion (IDInvert) by first training a novel domain-guided encoder which is able to produce in-domain latent code, and then performing domain-regularized optimization which involves the encoder as a regularizer to land the code inside the latent space when being finetuned. The in-domain codes produced by IDInvert enable high-quality real image editing with fixed GAN models.
Connect directly to RunwayML models with only a few lines of code to build web apps, chatbots, plugins, and more. Hosted Models live on the web and can be used anytime, anywhere, without requiring RunwayML to be open!
[…]
We've also released a JavaScript SDK alongside the new Hosted Models feature. Use it to bring a Hosted Model to your next project in just 3 lines of code.
David Ha trained SketchRNN with a flowchart dataset. You can test his live demo (mobile friendly) and his multi-prediction demo (not mobile-friendly).
The source code is available on GitHub.

Meet #HouseGAN: A relational generative adversarial network for graph-constrained house layout generation by Nelson Nauata & Chin-Yi Cheng at Autodesk Research in 2019.
Generate house layouts from architectural constraint graphs.
📝Paper → https://arxiv.org/abs/2003.06988
🧠Code → Coming soon!
This paper proposes a novel graph-constrained generative adversarial network, whose generator and discriminator are built upon relational architecture. The main idea is to encode the constraint into the graph structure of its relational networks. We have demonstrated the proposed architecture for a new house layout generation problem, whose task is to take an architectural constraint as a graph (i.e., the number and types of rooms with their spatial adjacency) and produce a set of axis-aligned bounding boxes of rooms. We measure the quality of generated house layouts with the three metrics: the realism, the diversity, and the compatibility with the input graph constraint. Our qualitative and quantitative evaluations over 117,000 real floor plan images demonstrate that the proposed approach outperforms existing methods and baselines. We will publicly share all our code and data.


A talk about machine learning, design, and creativity, at University of Arts Berlin on September 21, 2019, during the Fresh Eyes workshop at the Design Modelling Symposium conference.
Lobe is a web-based visual programming language to create and deploy machine learning models, founded in 2015 by Mike Matas, Adam Menges, and Markus Beissinger "to make deep learning accessible to everyone," recently acquired by Microsoft.
Lobe is an easy-to-use visual tool that lets you build custom deep learning models, quickly train them, and ship them directly in your app without writing code.
I saw a live demo at SmartGeometry earlier this year and I can't wait to play with it once its deployed on Microsoft's servers.
You can see a few examples at Lobe.ai. (They're looking for people to join their team.)
Watch this video to see examples of things people have built using Lobe and how to build your own custom deep learning models.

Last month, Jose Luis García del Castillo y López (@garciadelcast) and myself (@nonoesp) had the opportunity to lead the Mind Ex Machina cluster at SmartGeometry1 2018. (Watch on YouTube.)
This talk summarizes the projects that came out of our workshop, which intended to explore the possibilities of robot-human-ai interactions with the use of machine learning libraries and the Machina2 robotic control framework.
The SmartGeometry workshops and conferences were hosted in May 7–12, 2018, at the John H. Daniels Faculty of Architecture, Landscape, and Design at University of Toronto, Canada. The Mind Ex Machina cluster worked most of the time at the Autodesk Toronto Technology Office, located in the MaRS Discovery District.
I'm extremely thankful to Marc Webb for the following video, which provides a bit more insight on the things we worked on. (Watch on Vimeo.)

Shout-out to the impressive work of other clusters such as Fresh Eyes and Data Mining the City. See all of the videos here.
I think the whole group had a blast working on these projects—thanks! You can find notes and source code of the projects on GitHub (especially, in this repository).
🧠x🤖
SmartGeometry is a bi-annual workshop and conference, this year entitled sg2018: Machine Minds, at the University of Toronto, Canada, from 7th-12th May 2018. The sg2018 workshop and conference is a gathering of the global community of innovators and pioneers in the fields of architecture, design and engineering. ↩
Machina is an open-source project for action-based real-time control of mechanical actuators or, in more human terms, it allows you to talk to a robot and tell it what to do. Machina is developed and maintained by Jose Luis García del Castillo y López. ↩

Hey there! Until April 30, 2018, you can Participate to get a free portrait of a photo of your choosing. Just sign up with your e-mail and—optionally—upload the picture you would like to get a portrait of (or you can also do this later if you happen to be the winner). Enter at lourdes.ac/contest.

This looping series of photo2portrait pairs reminds me of the training sets you would need to feed certain machine learning algorithms (such as pix2pix) for them to learn how to generate an output image from an input image. If we were to train a neural network with photo2portrait pairs, the algorithm would try to learn how to generate a pencil portrait from a picture. (A training set for this purpose would, probably, need hundreds of photo2portrait pairs though.)

I generated multiple training sets for pix2pix for Suggestive Drawing, my thesis project at Harvard GSD. Most of the models I trained tried to generate a texture for a hand drawing. Flowers — in special daisies, sunflowers, roses, and tulips — happened to work particularly well.
It's a hand-sketched portrait.
Even though machine intelligence is enabling new modes of generating artwork, but the portraits you see here are (still) sketched on pencil by an artist—my mom—on paper. (As a curiosity, here is a looping gif of some of her many portraits of myself.)

We are currently accepting registrations for a raffle; You can win a free portrait! Just Enter the competition and you'll be able to select a photo later (of yourself, a relative, a friend, or even your pet). You can See all of her portraits on my mom's website.
Thanks so much and good luck!


