Phillip Isola did it again: Learning to generate line drawings that convey geometry and semantics
Less than three weeks ago, Caroline Mai Chan open-sourced a framework for unpaired line drawing generation on GitHub, accompanying a new publication by Phillip Isola, Frédo Durand, and Caroline Chan. Phillip Isola was formerly a postdoctoral scholar with Alyosha Efros at UC Berkeley. Together with Jun-Yan Zhu and Tinghui Zhou, Isola and Efros authored Pix2Pix in 2017, a framework for Image-to-Image Translation with Conditional Adversarial Networks that was presented at the CVPR conference. Isola is now an associate professor at MIT in EECS studying computer vision, machine learning, and artificial intelligence.
According to Isola's list of papers, it's been 39 publications since Pix2Pix was published, and he's contributed with a daunting amount of innovations.

Chan, Durand, and Isola's latest publication, titled Informative Drawings: Learning to generate line drawings that convey geometry and semantics, proposes an image translation framework that generates line drawings from photographs without the need for paired training data or human judgment in the training process, a type of machine learning algorithm known as unsupervised, because the data used for training doesn't need to be labeled manually and photos don't need to be paired with sketches of the same thing.
We introduce a geometry loss that predicts depth information from the image features of a line drawing and a semantic loss that matches the CLIP features of a line drawing with its corresponding photograph. Our approach outperforms state-of-the-art unpaired image translation and line drawing generation methods for creating line drawings from arbitrary photographs.
Here's an interactive HuggingFace demo which maps pictures to two different drawing styles explicitly instilling geometry and semantic information. The results are surprising.
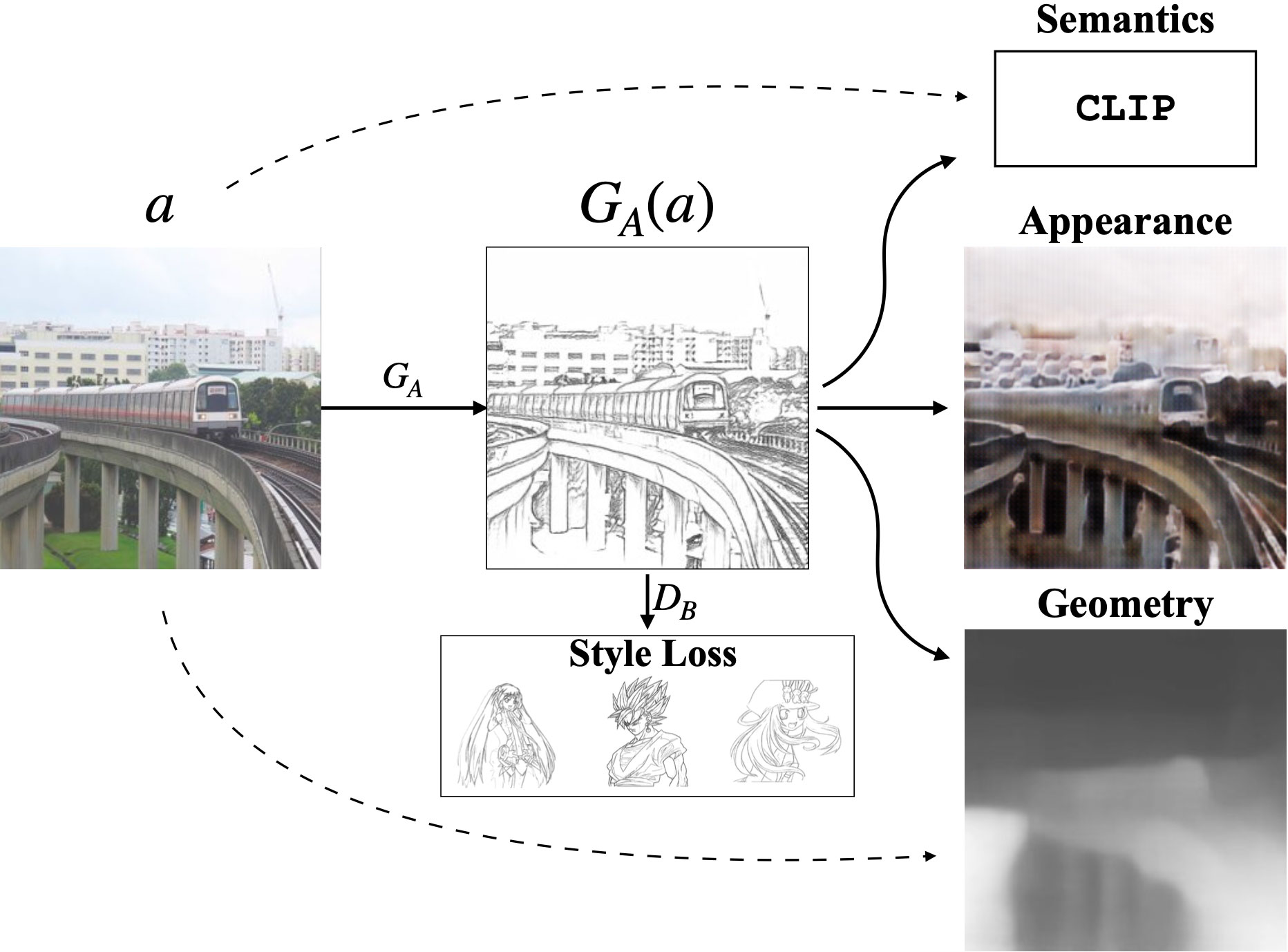
The model uses four main losses. An adversarial loss with a discriminator encourages generated line drawings to resemble those drawings in the training set. The other three losses—CLIP, appearance, and geometry—enforce the line drawing to communicate semantic meaning, appearance, and geometry, respectively.